Data
Přehled
Modul Data slouží ke sdružování více datových zdrojů do jednoho logického celku. Datová kolekce představuje centrální kontejner dat, který lze následně využívat v AI agentech, workflows nebo analytických nástrojích v Siesta AI.
Každá kolekce:
- má vlastní název a popis,
- obsahuje jeden nebo více datových zdrojů,
- umožňuje řídit a organizovat data podle jejich účelu.
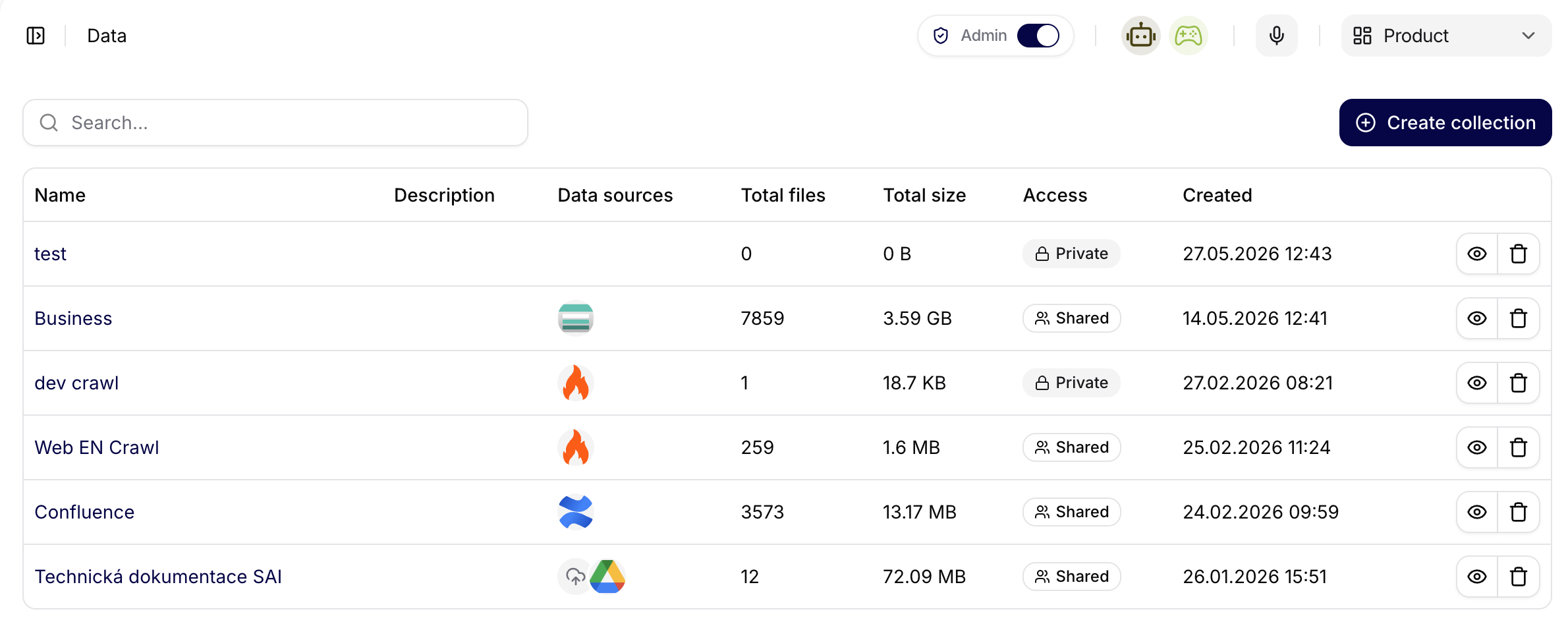
Přehled datových kolekcí
Na hlavní obrazovce Kolekce dat je zobrazen seznam všech vytvořených kolekcí ve formě tabulky.
Zobrazené sloupce:
- Name – název datové kolekce
- Description – stručný popis účelu kolekce
- Data Sources – ikony připojených datových zdrojů
- Total files - celkový počet připojených souborů
- Total size - celková velikost všech připojených souborů
- Created – datum a čas vytvoření
- Akce – další možnosti práce s kolekcí, možnost zobrazení detailů a smazání kolekce
V horní části obrazovky je dostupné:
- vyhledávání kolekcí,
- tlačítko Vytvořit kolekci.
Screenshot ukazuje přehled Data pro tým Product. Každý řádek představuje datovou kolekci a obsahuje ikony připojených zdrojů, počet souborů, celkovou velikost, přístup, datum vytvoření a akce nad kolekcí. Tento pohled pomáhá rychle poznat, které kolekce obsahují reálný obsah, které jsou sdílené a které jsou zatím prázdné nebo soukromé.
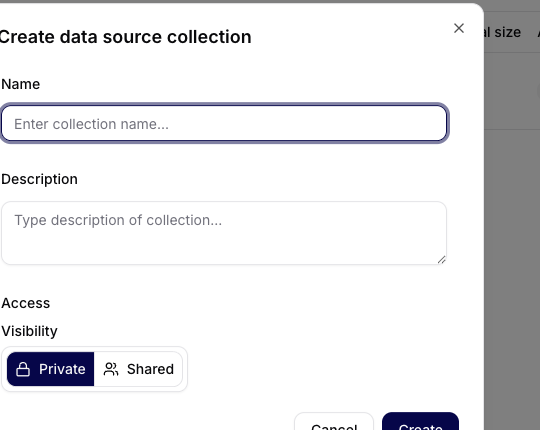
Vytvoření nové datové kolekce
Po kliknutí na Vytvořit kolekci se otevře dialog pro založení nové kolekce.
Povinná pole
- Název – jednoznačný název datové kolekce (např. Neurology Research Results – Big Data Collection).
- Popis – stručný popis obsahu a účelu kolekce.
Akce
- Zrušit – zavře dialog bez uložení
- Vytvořit – vytvoří novou datovou kolekci
Detail datové kolekce
Po otevření konkrétní kolekce se zobrazí její detailní stránka.
Zobrazené informace:
- název kolekce,
- přehled připojených datových zdrojů.
Součástí stránky jsou tlačítko Upravit data kolekci a Přidat datový zdroj.
Přidání datového zdroje do kolekce
Kliknutím na Přidat datový zdroj se otevře výběr typu datového zdroje.
Dostupné možnosti
- Manual Upload – ruční nahrání souborů
- Azure Storage Account
- Jira
- Firecrawl
- Google Drive
- Confluence

Konfigurace jednotlivých datových zdrojů
Jira
Pro Jira datový zdroj nastavíte:
- Name a Description,
- Connection ID (napojený Jira konektor),
- Sync schedule,
- Data collection (možnost přesunout zdroj do jiné kolekce),
- Project Key,
- sekce Retriever a Processing.
Přímý odkaz na konektor: Jira.
Azure Storage Account
Pro Azure Storage Account datový zdroj nastavíte:
- Name a Description,
- Connection ID (napojený Azure Storage konektor),
- Sync schedule,
- Data collection (možnost přesunout zdroj do jiné kolekce),
- seznam Blobs (včetně přidání/smazání položky),
- sekce Retriever a Processing.
Přímý odkaz na konektor: Azure Storage Account.
Confluence
Pro Confluence datový zdroj nastavíte:
- Name a Description,
- Connection ID (napojený Confluence konektor),
- Sync schedule,
- Data collection (možnost přesunout zdroj do jiné kolekce),
- Space Key.
Přímý odkaz na konektor: Confluence.
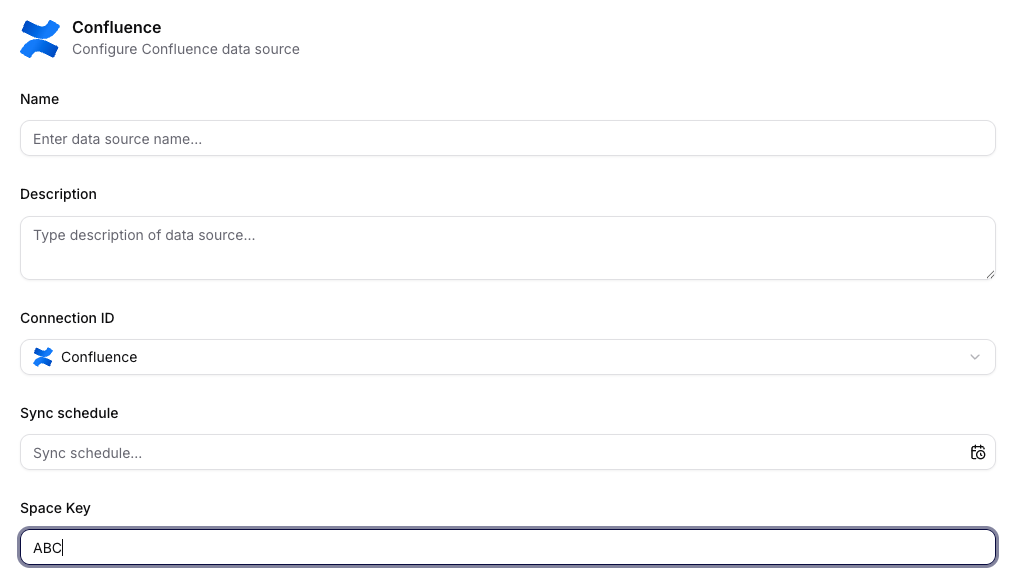
Firecrawl
Pro Firecrawl datový zdroj nastavíte:
- Name a Description,
- Connection ID (napojený Firecrawl konektor),
- Sync schedule,
- Data collection (možnost přesunout zdroj do jiné kolekce),
- Scrape type,
- Scrape URL,
- Limit a volitelné regex filtry (např.
Include paths regex).
Přímý odkaz na konektor: Firecrawl.
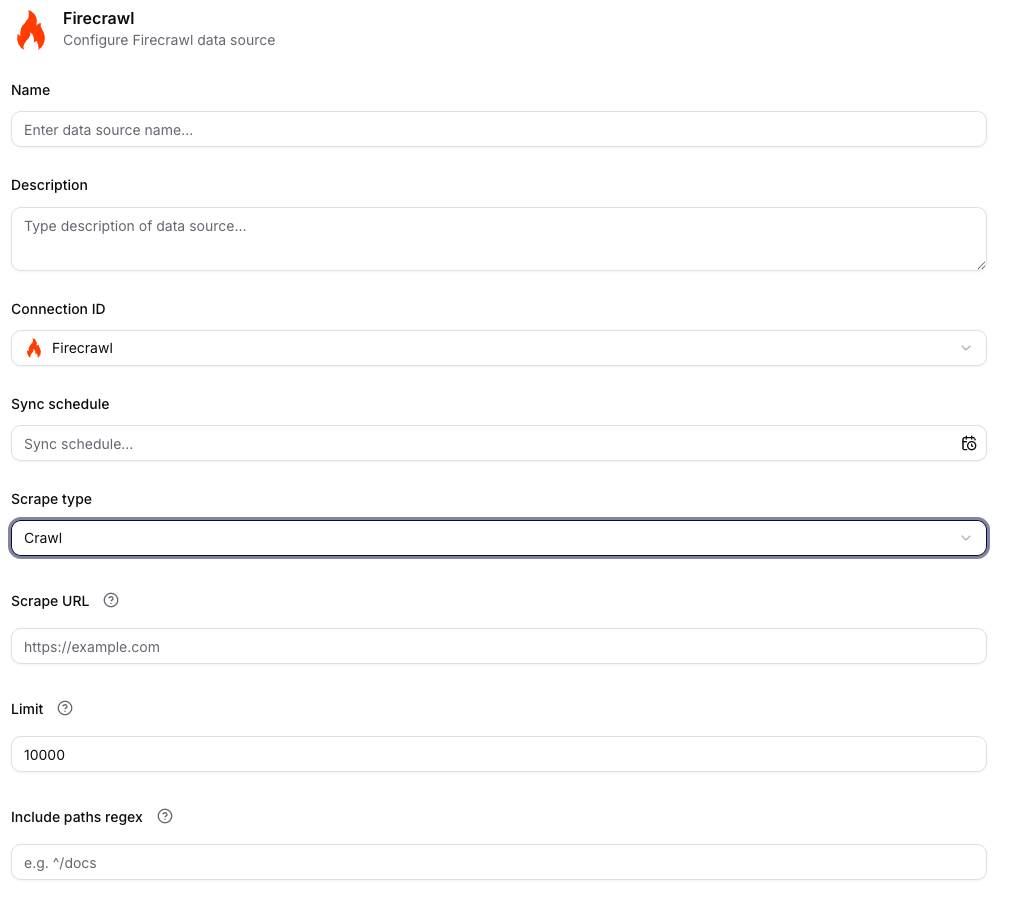
Google Drive
Pro Google Drive datový zdroj nastavíte:
- Name a Description,
- Connection ID (napojený Google Drive konektor),
- Sync schedule,
- seznam Folders (včetně přidání/smazání položky),
- Data collection (možnost přesunout zdroj do jiné kolekce),
- sekce Retriever a Processing.
Přímý odkaz na konektor: Google Drive.
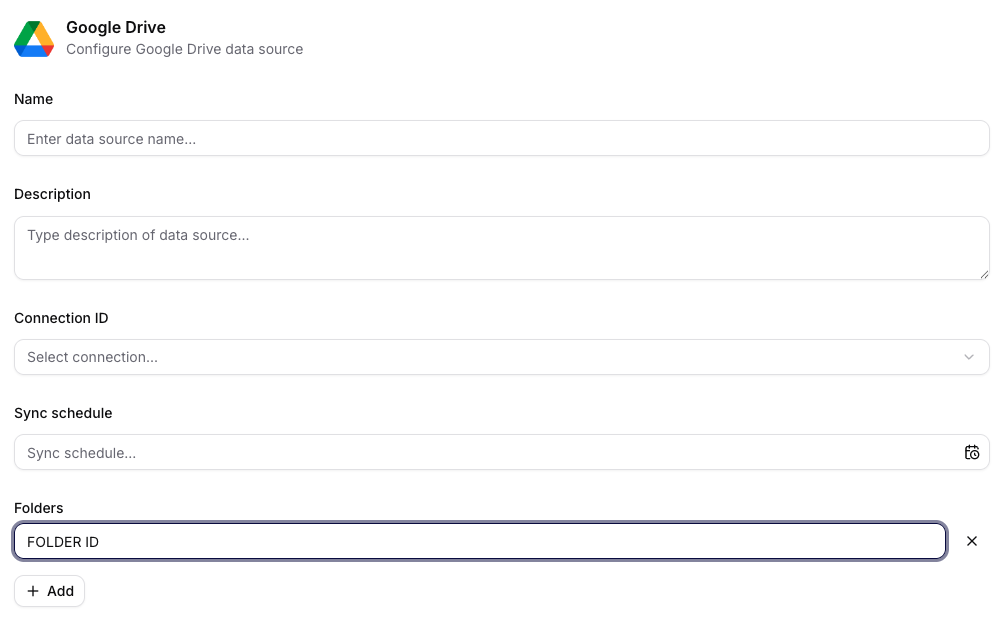
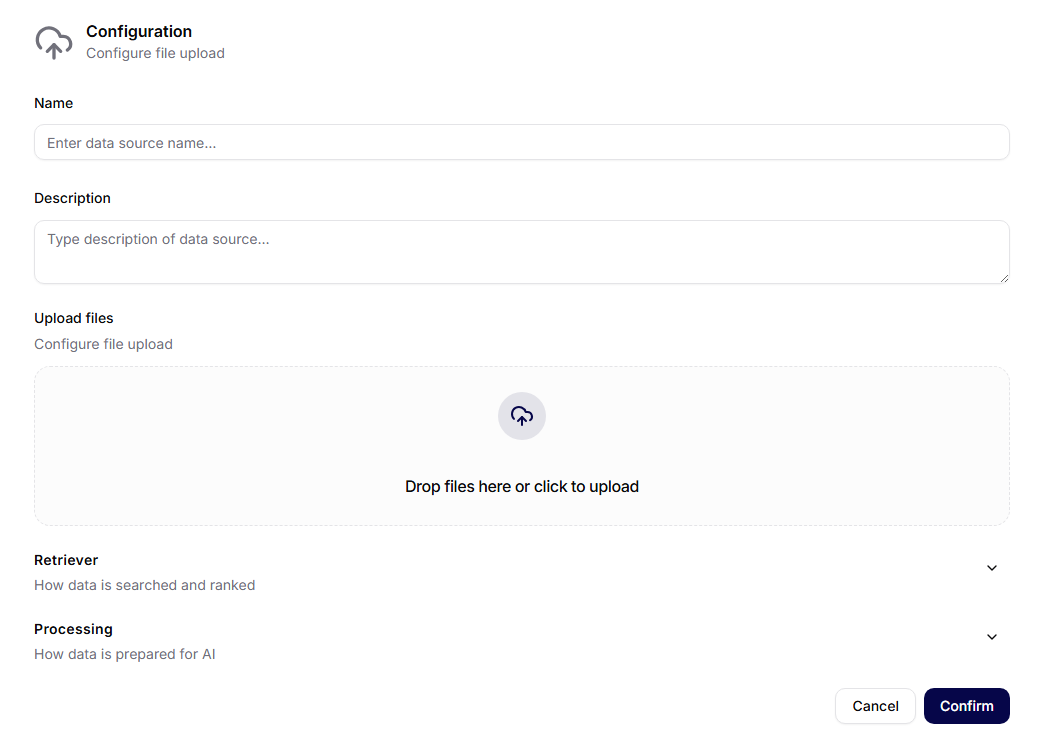
Manual Upload
Pro Manual Upload datový zdroj nastavíte:
- Name a Description,
- sekci Upload files pro nahrání souborů,
- Data collection (možnost přesunout zdroj do jiné kolekce),
- sekce Retriever a Processing.
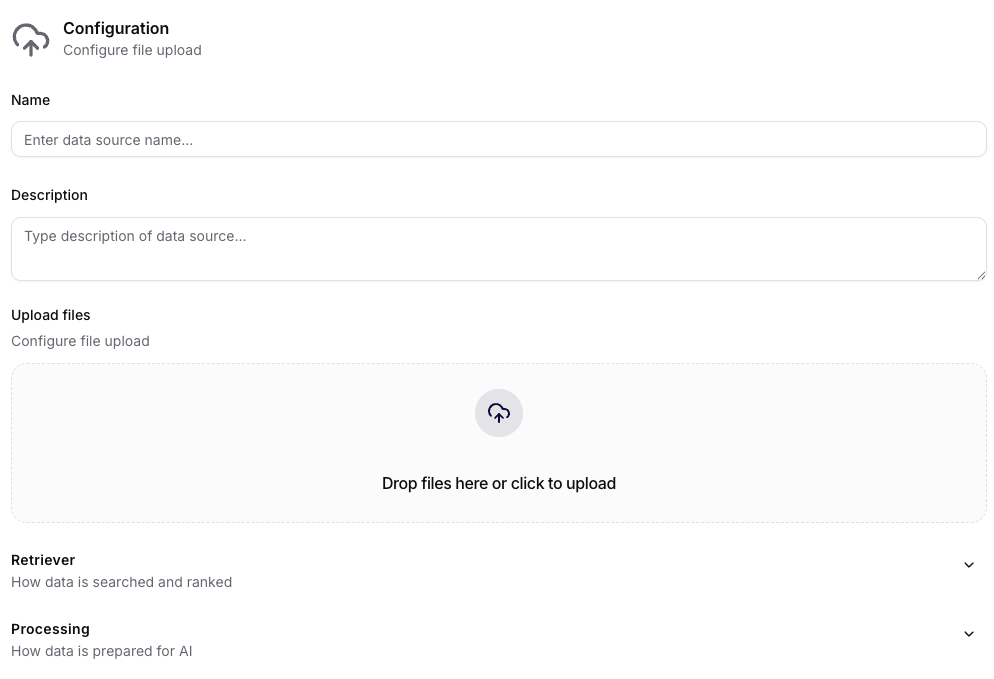
Retriever a Processing
V těchto sekcích lze řídit způsob vyhledávání i přípravy dat pro AI:
- Retriever:
Skip LLM query rewrite,Skip LLM re-ranking,Max results count - Processing:
Chunking strategy,Advanced content extraction,JSON Features,JSON Metadata Definitions
Nastavení Retriever a Processing lze měnit i u zdrojů Azure Storage Account, Manual Upload a Google Drive.
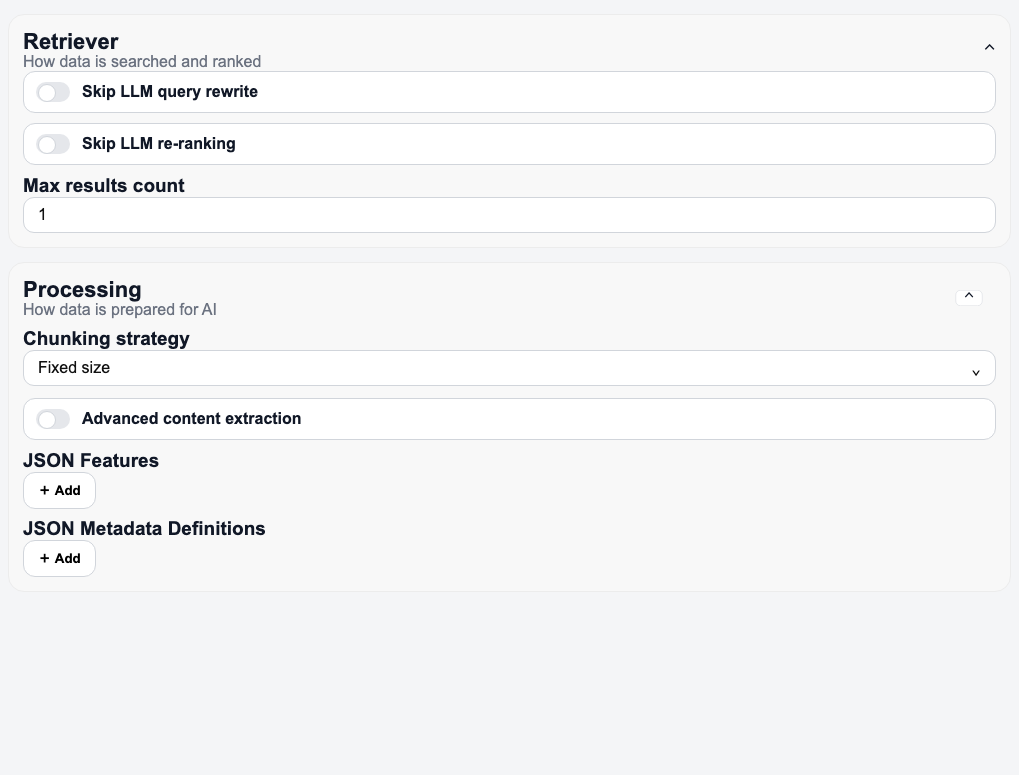
Detail datového zdroje (Overview, Configuration, Files, Logs)
Každý datový zdroj má v detailu vlastní záložky:
- Overview
- Configuration
- Files
- Logs
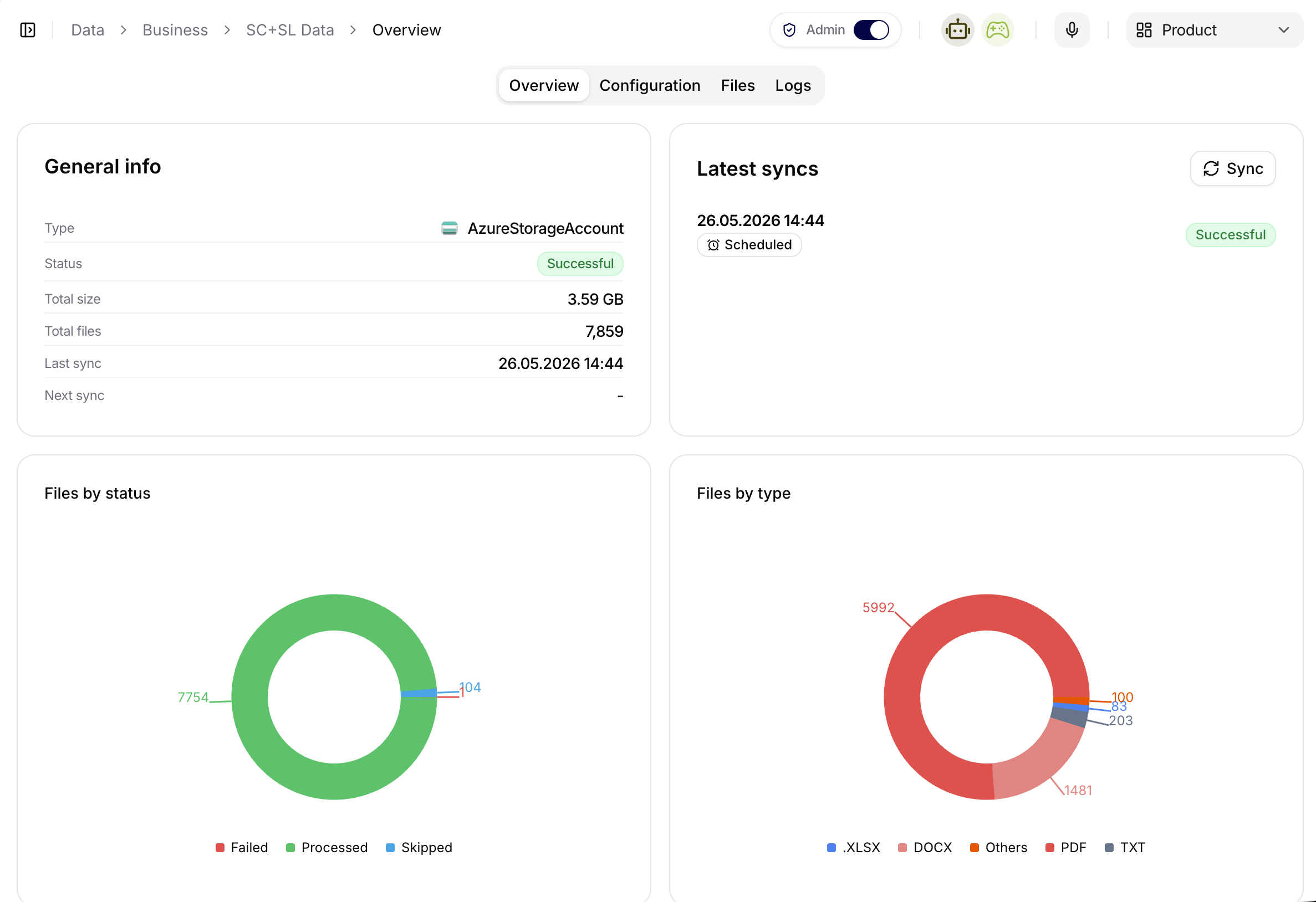
Overview
Záložka Overview poskytuje rychlý přehled:
- typ zdroje,
- stav posledních synchronizací,
- počet souborů a celkovou velikost,
- základní statistiky podle stavu a typu souborů.
Screenshot detailu zdroje ukazuje zdroj SC+SL Data v kolekci Business. Karta General info potvrzuje typ zdroje, stav, celkovou velikost, počet souborů a poslední synchronizaci. Karta Latest syncs ukazuje poslední synchronizační běh a jeho výsledek. Spodní grafy shrnují soubory podle processing statusu a typu souboru, takže admin rychle pozná chyby ve zpracování nebo nečekané složení dokumentů.
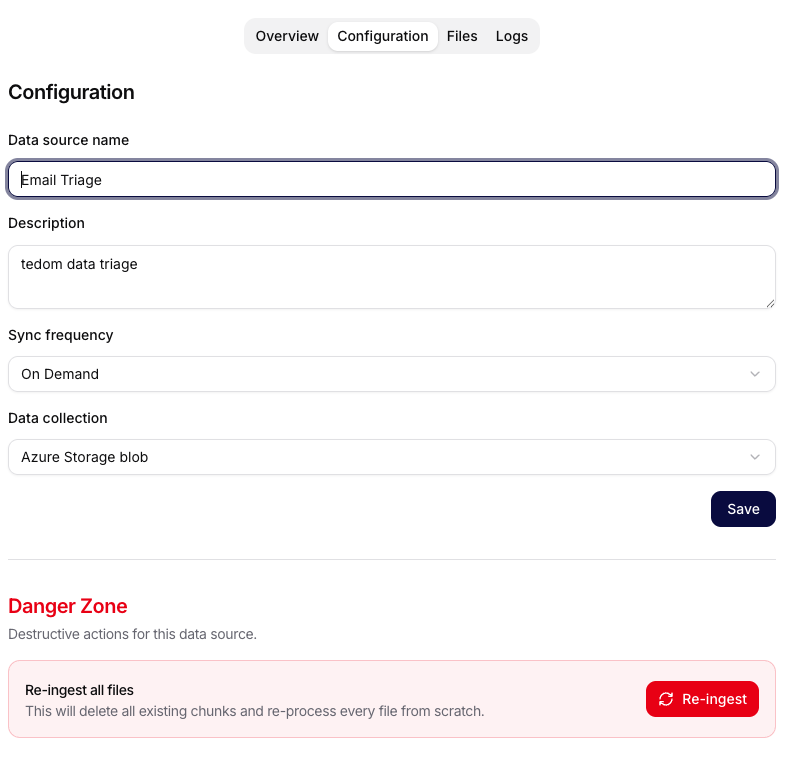
Configuration
V záložce Configuration můžete upravovat nastavení datového zdroje (např. název, popis, frekvenci synchronizace, přiřazenou kolekci). Přes pole Data collection lze datový zdroj kdykoliv přesunout mezi kolekcemi. Součástí je i Danger Zone pro destruktivní akce jako re-ingest všech souborů.
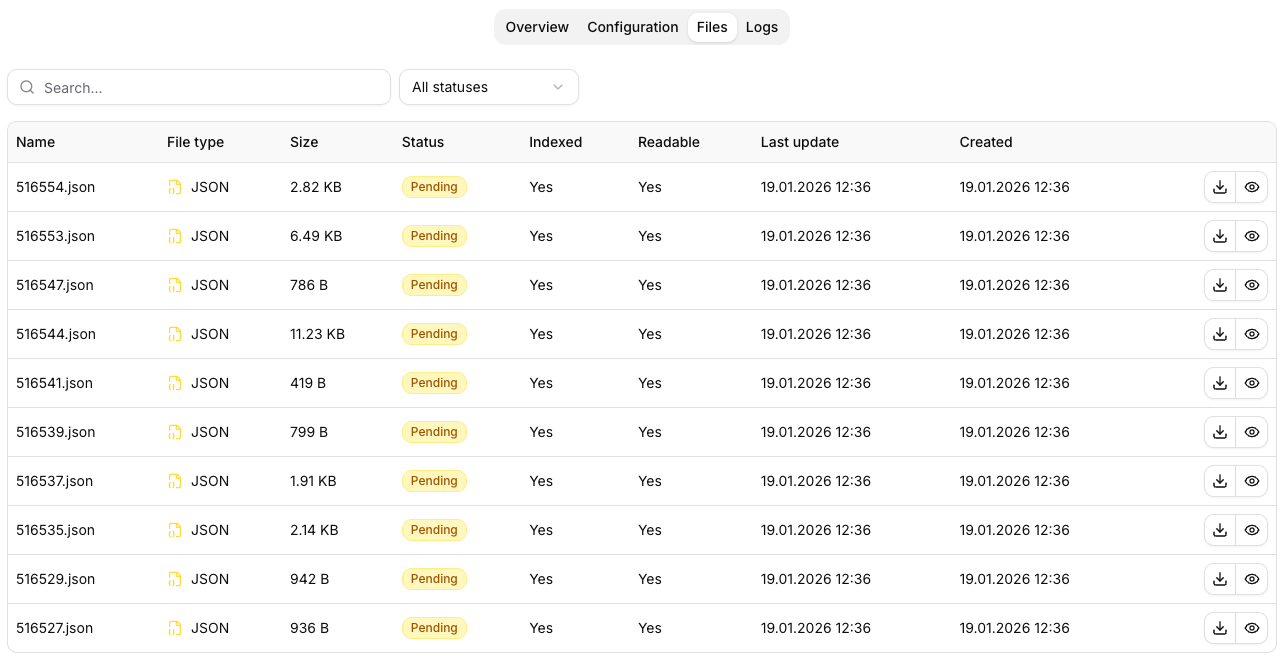
Files
V záložce Files je přehled souborů daného zdroje:
- filtrace podle stavu,
- metadata souborů (typ, velikost, status, indexed/readable),
- možnost otevřít detail konkrétního souboru.
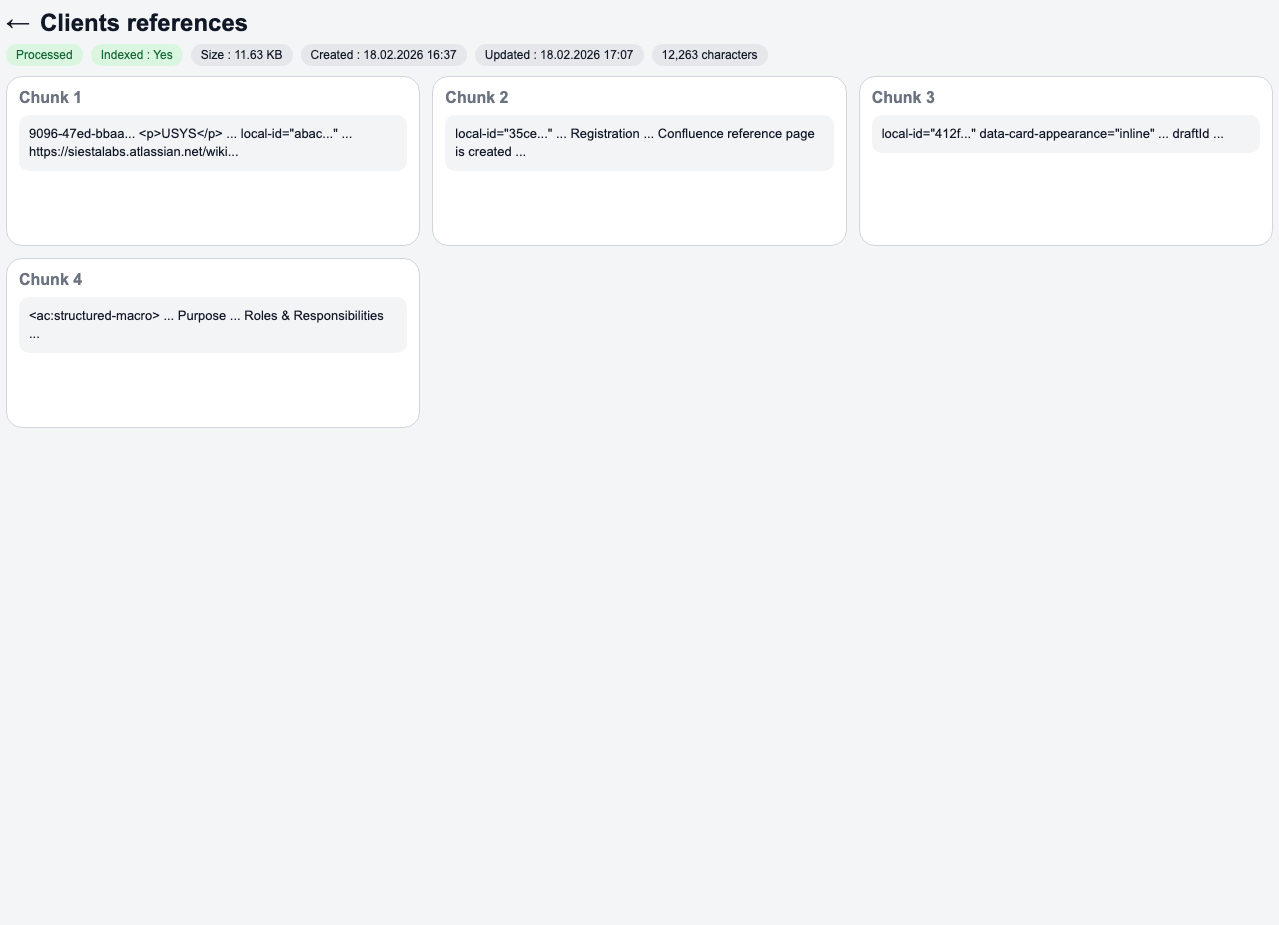
Detail souboru a chunking
V detailu souboru je vidět, jak byl dokument rozchunkovaný pro AI indexing. Zobrazuje se stav souboru, metadata a jednotlivé chunky, které vstupují do retrieval pipeline.
Logs
V záložce Logs najdete historii synchronizací a zpracování:
- datum spuštění a dokončení,
- počty zpracovaných/přeskočených položek,
- trigger synchronizace (např. plánovaně).

Napojení datových kolekcí na agenta
Datové kolekce se následně přiřazují k agentům v jejich nastavení. Podrobnosti najdete v části Konfigurace agenta.
Typické využití datových kolekcí
Datové kolekce slouží zejména k:
- organizaci většího množství souborů,
- sdružování dat podle tématu nebo projektu,
- vytváření jednotného zdroje pravdy pro AI agenty,
- opakovanému použití stejných dat v různých workflows,
- škálování práce s daty bez nutnosti jejich duplikace.
Shrnutí
Datové kolekce v Siesta AI umožňují přehlednou správu dat a jejich efektivní využití napříč celou platformou. Správně strukturované kolekce jsou základem pro kvalitní výstupy AI agentů a automatizovaných workflows.