Datos
Resumen
El módulo Datos se utiliza para agrupar múltiples fuentes de datos en una sola entidad lógica. La colección de datos representa un contenedor central de datos que se puede utilizar posteriormente en agentes de IA, flujos de trabajo o herramientas analíticas en Siesta AI.
Cada colección:
- tiene un nombre y una descripción propios,
- contiene una o más fuentes de datos,
- permite gestionar y organizar los datos según su propósito.
Resumen de colecciones de datos
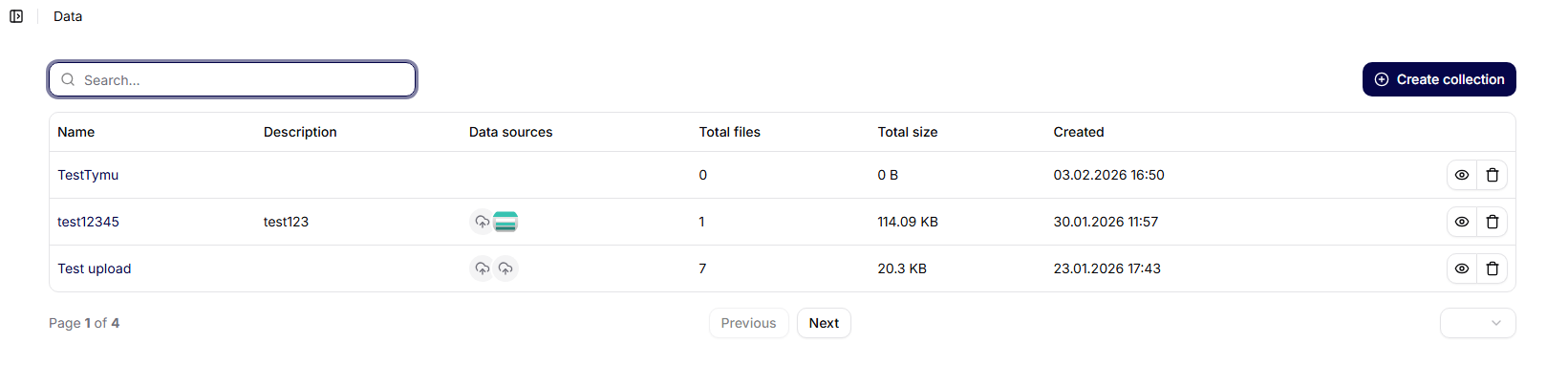
En la pantalla principal de Colecciones de datos se muestra una lista de todas las colecciones creadas en forma de tabla.
Columnas mostradas:
- Nombre – nombre de la colección de datos
- Descripción – breve descripción del propósito de la colección
- Fuentes de datos – número de fuentes de datos conectadas
- Creado – fecha y hora de creación
- Acciones – otras opciones de trabajo con la colección
En la parte superior de la pantalla está disponible:
- búsqueda de colecciones,
- botón Crear colección.
Creación de una nueva colección de datos
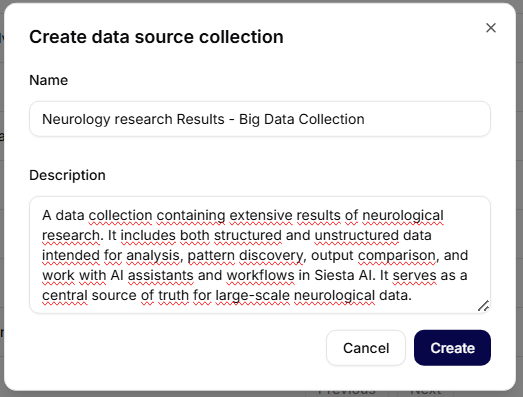
Al hacer clic en Crear colección, se abre un diálogo para crear una nueva colección.
Campos obligatorios
- Nombre – nombre único de la colección de datos (por ejemplo, Resultados de Investigación en Neurología – Colección de Big Data).
- Descripción – breve descripción del contenido y propósito de la colección.
Acciones
- Cancelar – cierra el diálogo sin guardar
- Crear – crea una nueva colección de datos
Detalle de la colección de datos
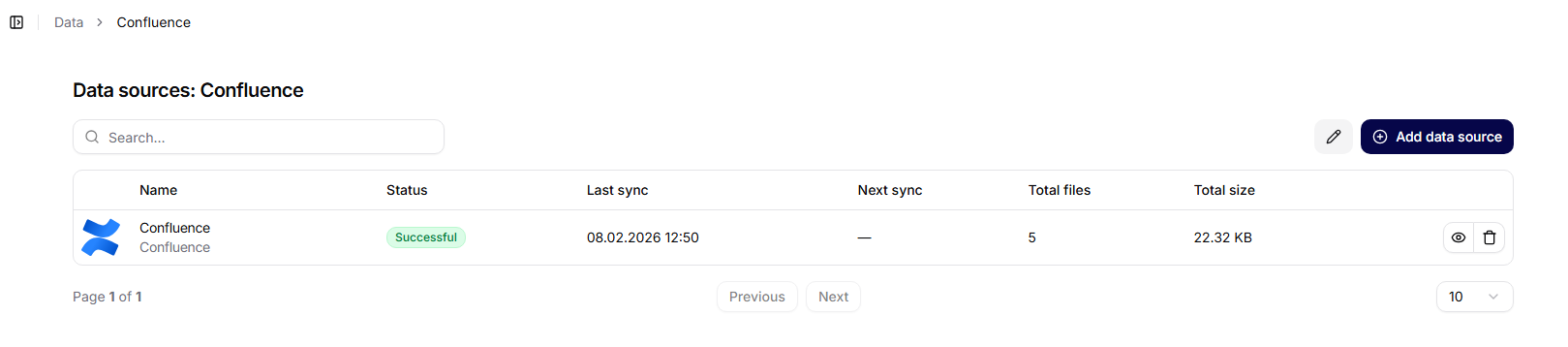
Al abrir una colección específica, se muestra su página de detalles.
Información mostrada:
- nombre de la colección,
- fecha de creación,
- resumen de las fuentes de datos conectadas.
La página incluye un botón Agregar fuente de datos.
Agregar fuente de datos a la colección
Al hacer clic en Agregar fuente de datos, se abre la selección del tipo de fuente de datos.
Opciones disponibles
- Carga Manual – carga manual de archivos
- Google Drive (en preparación)
- SharePoint (en preparación)
- Azure Storage (en preparación)
- Jira (en preparación)
En la versión actual, está disponible la carga manual de archivos.

Configuración de la fuente de datos (Carga Manual)
Después de seleccionar Carga Manual, se muestra el formulario de configuración.
Campos de configuración
- Nombre – nombre de la fuente de datos (por ejemplo, Big Data).
- Descripción – descripción opcional del contenido de la fuente de datos.
- Cargar archivos – opción para arrastrar archivos a la zona designada o hacer clic para seleccionar archivos desde la computadora.
- Funciones JSON (opcional) – se utiliza para definir funciones personalizadas para trabajar con los datos.
- Definiciones de metadatos JSON (opcional) – permite agregar metadatos estructurados a la fuente de datos.
Acciones
- Cancelar – sale de la configuración sin guardar
- Confirmar – guarda la fuente de datos y comienza su procesamiento
Estado de la fuente de datos
Cada fuente de datos tiene su propio estado de procesamiento:
- En procesamiento – los datos están siendo analizados e indexados
- Procesado – la fuente de datos está lista para su uso
El estado es visible en la tabla de fuentes de datos en el detalle de la colección.
Conexión de colecciones de datos al agente
Las colecciones de datos se asignan posteriormente a los agentes en su configuración. Los detalles se pueden encontrar en la sección Configuración del agente.
Uso típico de colecciones de datos
Las colecciones de datos se utilizan principalmente para:
- organizar una mayor cantidad de archivos,
- agrupar datos por tema o proyecto,
- crear una única fuente de verdad para los agentes de IA,
- reutilizar los mismos datos en diferentes flujos de trabajo,
- escalar el trabajo con datos sin necesidad de duplicarlos.
Resumen
Las colecciones de datos en Siesta AI permiten una gestión clara de los datos y su uso efectivo a través de toda la plataforma. Las colecciones bien estructuradas son la base para obtener resultados de calidad de los agentes de IA y flujos de trabajo automatizados.