Data
Oversigt
Modulet Data bruges til at samle flere datakilder i en enkelt logisk enhed. Datakollektionen repræsenterer en central beholder for data, som derefter kan anvendes i AI-agenter, workflows eller analytiske værktøjer i Siesta AI.
Hver kollektion:
- har et eget navn og beskrivelse,
- indeholder en eller flere datakilder,
- gør det muligt at styre og organisere data efter deres formål.
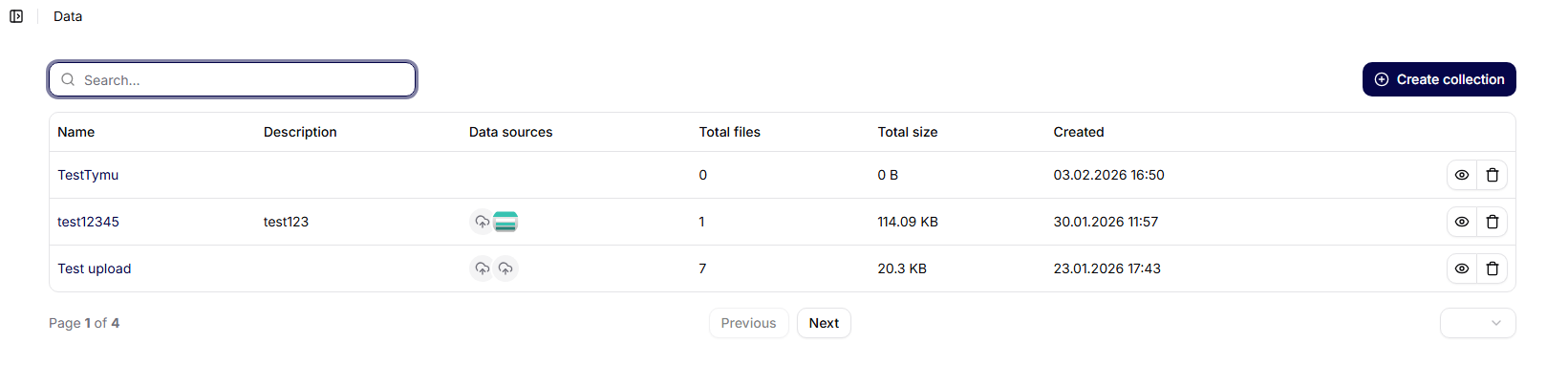
Oversigt over datakollektioner
På hovedskærmen for Datakollektioner vises en liste over alle oprettede kollektioner i form af en tabel.
Viste kolonner:
- Navn – navnet på datakollektionen
- Beskrivelse – kort beskrivelse af formålet med kollektionen
- Datakilder – antal tilsluttede datakilder
- Oprettet – dato og tidspunkt for oprettelse
- Handlinger – yderligere muligheder for arbejde med kollektionen
Øverst på skærmen er der tilgængeligt:
- søgning efter kollektioner,
- knappen Opret kollektion.
Oprettelse af en ny datakollektion
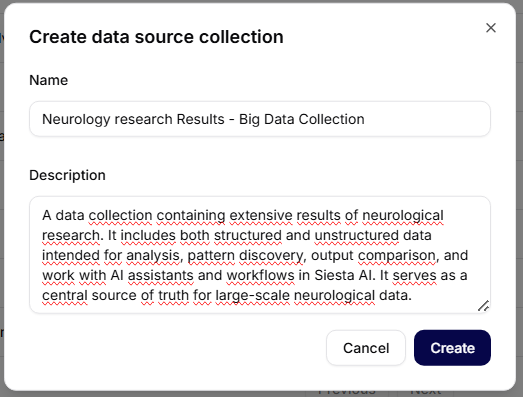
Efter at have klikket på Opret kollektion åbnes en dialog for oprettelse af en ny kollektion.
Obligatoriske felter
- Navn – entydigt navn på datakollektionen (f.eks. Neurology Research Results – Big Data Collection).
- Beskrivelse – kort beskrivelse af indholdet og formålet med kollektionen.
Handlinger
- Annuller – lukker dialogen uden at gemme
- Opret – opretter en ny datakollektion
Detalje om datakollektionen
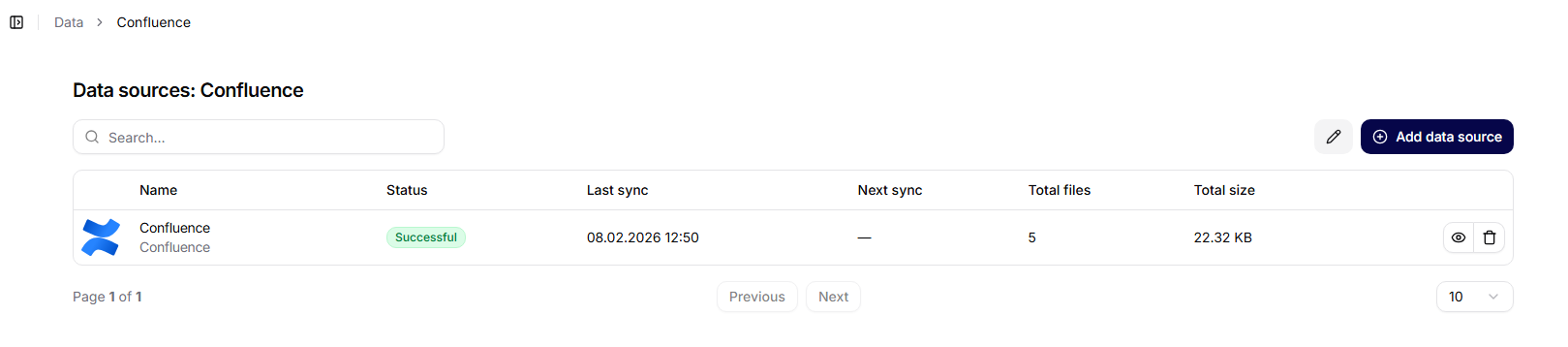
Når en specifik kollektion åbnes, vises dens detaljeside.
Viste oplysninger:
- navnet på kollektionen,
- dato for oprettelse,
- oversigt over tilsluttede datakilder.
En del af siden er knappen Tilføj datakilde.
Tilføjelse af datakilde til kollektionen
Ved at klikke på Tilføj datakilde åbnes valget af datakildetype.
Tilgængelige muligheder
- Manual Upload – manuel upload af filer
- Google Drive (under udvikling)
- SharePoint (under udvikling)
- Azure Storage (under udvikling)
- Jira (under udvikling)
I den aktuelle version er manuel upload af filer tilgængelig.

Konfiguration af datakilde (Manual Upload)
Efter at have valgt Manual Upload vises konfigurationsformularen.
Konfigurationsfelter
- Navn – navnet på datakilden (f.eks. Big Data).
- Beskrivelse – valgfri beskrivelse af indholdet af datakilden.
- Upload filer – mulighed for at trække filer ind i det markerede område eller klikke for at vælge filer fra computeren.
- JSON-funktioner (valgfrit) – bruges til at definere brugerdefinerede funktioner til arbejde med data.
- JSON metadata definitioner (valgfrit) – giver mulighed for at tilføje strukturerede metadata til datakilden.
Handlinger
- Annuller – forlader konfigurationen uden at gemme
- Bekræft – gemmer datakilden og starter dens behandling
Konfiguration af manuel upload
Status for datakilden
Hver datakilde har sin egen behandlingsstatus:
- Behandles – data analyseres og indekseres
- Behandlet – datakilden er klar til brug
Status er synlig i tabellen over datakilder i detaljen for kollektionen.
Tilknytning af datakollektioner til agenten
Datakollektioner tildeles derefter til agenter i deres indstillinger. Du kan finde detaljer i afsnittet Konfiguration af agent.
Typisk anvendelse af datakollektioner
Datakollektioner bruges primært til:
- organisering af større mængder filer,
- samling af data efter emne eller projekt,
- oprettelse af en ensartet kilde til sandhed for AI-agenter,
- gentagen brug af de samme data i forskellige workflows,
- skalering af arbejdet med data uden behov for duplikering.
Resumé
Datakollektioner i Siesta AI muliggør en overskuelig administration af data og deres effektive anvendelse på tværs af hele platformen. Korrekt strukturerede kollektioner er grundlaget for kvalitetsudgange fra AI-agenter og automatiserede workflows.