Data
Översikt
Modulen Data används för att sammanföra flera datakällor till en logisk enhet. Datakollektionen representerar en central behållare för data som sedan kan användas i AI-agenter, arbetsflöden eller analytiska verktyg i Siesta AI.
Varje kollektion:
- har ett eget namn och beskrivning,
- innehåller en eller flera datakällor,
- möjliggör att styra och organisera data efter deras syfte.
Översikt över datakollektioner
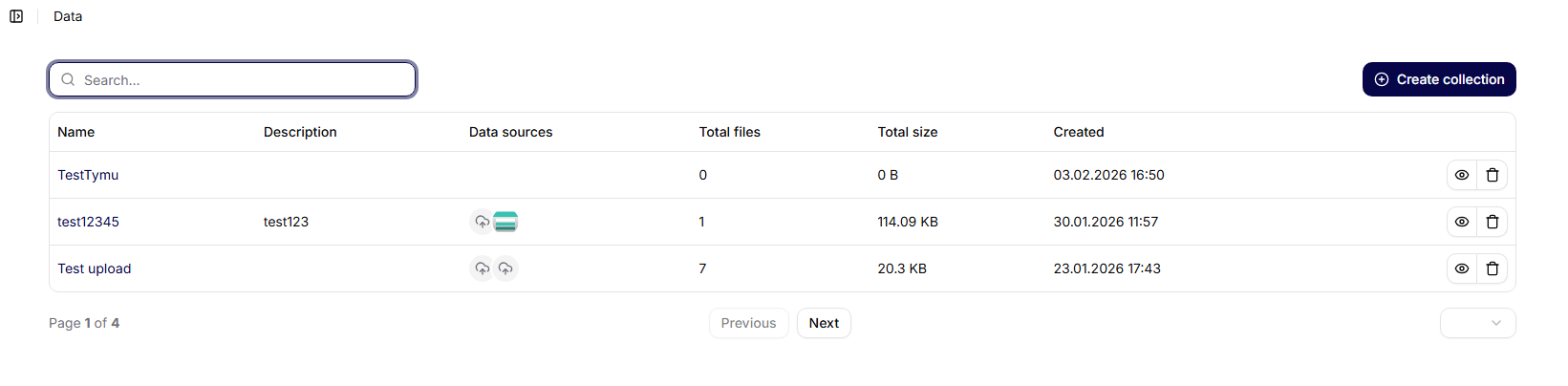
På huvudskärmen för Datakollektioner visas en lista över alla skapade kollektioner i form av en tabell.
Visade kolumner:
- Namn – namnet på datakollektionen
- Beskrivning – en kort beskrivning av kollektionens syfte
- Datakällor – antal anslutna datakällor
- Skapat – datum och tid för skapande
- Åtgärder – ytterligare alternativ för att arbeta med kollektionen
I den övre delen av skärmen finns tillgängligt:
- sökning av kollektioner,
- knappen Skapa kollektion.
Skapa en ny datakollektion
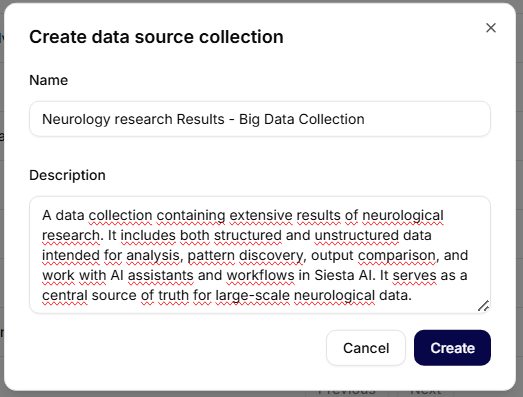
Efter att ha klickat på Skapa kollektion öppnas en dialog för att skapa en ny kollektion.
Obligatoriska fält
- Namn – ett unikt namn för datakollektionen (t.ex. Neurology Research Results – Big Data Collection).
- Beskrivning – en kort beskrivning av innehållet och syftet med kollektionen.
Åtgärder
- Avbryt – stänger dialogen utan att spara
- Skapa – skapar en ny datakollektion
Detalj om datakollektionen
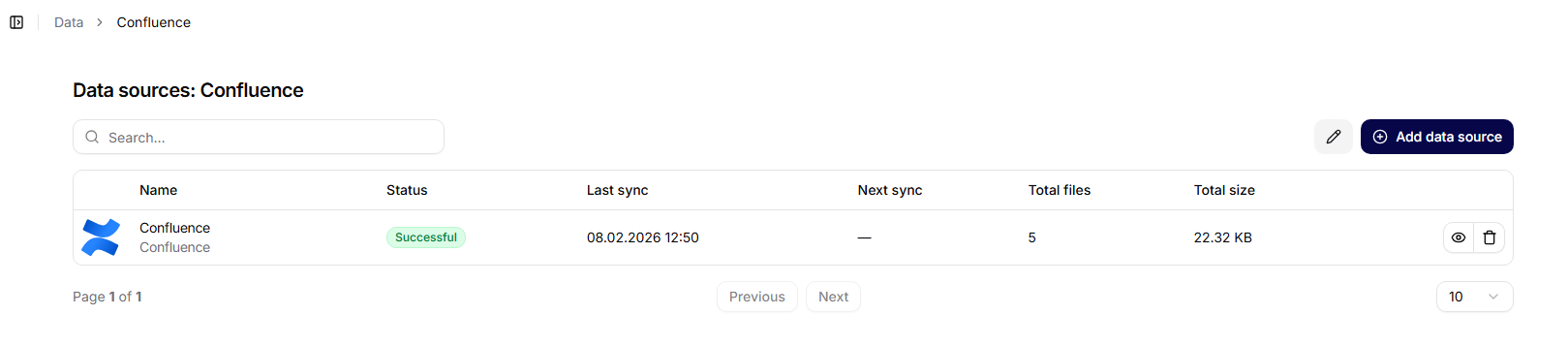
När en specifik kollektion öppnas visas dess detaljsida.
Visade informationer:
- kollektionens namn,
- skapelsedatum,
- översikt över anslutna datakällor.
En del av sidan är knappen Lägg till datakälla.
Lägga till datakälla i kollektionen
Genom att klicka på Lägg till datakälla öppnas ett val av typ av datakälla.
Tillgängliga alternativ
- Manual Upload – manuell uppladdning av filer
- Google Drive (under utveckling)
- SharePoint (under utveckling)
- Azure Storage (under utveckling)
- Jira (under utveckling)
I den aktuella versionen är manuell uppladdning av filer tillgänglig.

Konfiguration av datakälla (Manual Upload)
Efter att ha valt Manual Upload visas ett konfigurationsformulär.
Konfigurationsfält
- Namn – namnet på datakällan (t.ex. Big Data).
- Beskrivning – valfri beskrivning av datakällans innehåll.
- Ladda upp filer – möjlighet att dra och släppa filer i det markerade området, eller klicka för att välja filer från datorn.
- JSON-funktioner (valfritt) – används för att definiera egna funktioner för att arbeta med data.
- JSON-metadata definitioner (valfritt) – möjliggör att lägga till strukturerad metadata till datakällan.
Åtgärder
- Avbryt – lämnar konfigurationen utan att spara
- Bekräfta – sparar datakällan och startar dess bearbetning
Konfiguration av manuell uppladdning
Status för datakällan
Varje datakälla har sin egen bearbetningsstatus:
- Bearbetas – data analyseras och indexeras
- Bearbetad – datakällan är redo att användas
Statusen är synlig i tabellen över datakällor i kollektionens detaljvy.
Koppling av datakollektioner till agenten
Datakollektioner tilldelas sedan agenter i deras inställningar. Mer information finns i avsnittet Konfiguration av agent.
Typisk användning av datakollektioner
Datakollektioner används främst för:
- organisering av större mängder filer,
- sammanställning av data efter ämne eller projekt,
- skapande av en enhetlig sanning för AI-agenter,
- återanvändning av samma data i olika arbetsflöden,
- skalning av arbete med data utan behov av duplicering.
Sammanfattning
Datakollektioner i Siesta AI möjliggör en överskådlig hantering av data och deras effektiva användning över hela plattformen. Rätt strukturerade kollektioner är grunden för kvalitativa resultat från AI-agenter och automatiserade arbetsflöden.