Data
Oversikt
Data-modulen brukes til å samle flere datakilder i en logisk enhet. Datakolleksjonen representerer en sentral beholder for data som kan brukes i AI-agenter, arbeidsflyter eller analytiske verktøy i Siesta AI.
Hver samling:
- har et eget navn og beskrivelse,
- inneholder en eller flere datakilder,
- gjør det mulig å styre og organisere data etter deres formål.
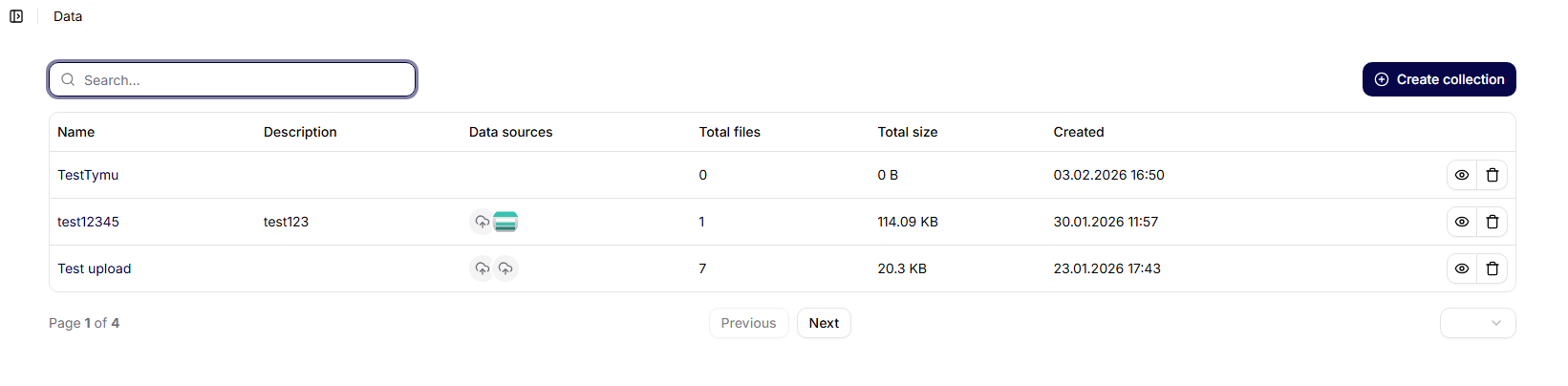
Oversikt over datakolleksjoner
På hovedskjermen for Datakolleksjoner vises en liste over alle opprettede samlinger i form av en tabell.
Viste kolonner:
- Navn – navnet på datakolleksjonen
- Beskrivelse – kort beskrivelse av formålet med samlingen
- Datakilder – antall tilkoblede datakilder
- Opprettet – dato og klokkeslett for opprettelse
- Handlinger – ytterligere muligheter for arbeid med samlingen
Øverst på skjermen er tilgjengelig:
- søkefunksjon for samlinger,
- knappen Opprett samling.
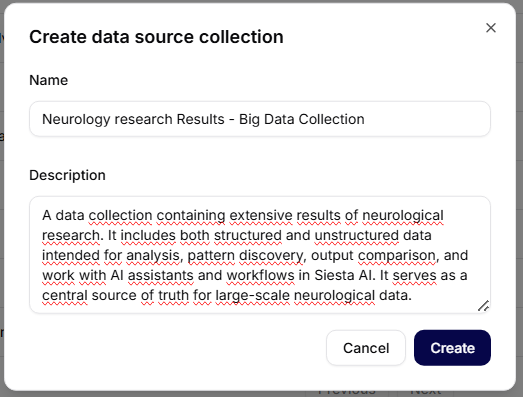
Opprettelse av ny datakolleksjon
Når du klikker på Opprett samling, åpnes en dialog for opprettelse av en ny samling.
Obligatoriske felt
- Navn – entydig navn på datakolleksjonen (f.eks. Neurology Research Results – Big Data Collection).
- Beskrivelse – kort beskrivelse av innholdet og formålet med samlingen.
Handlinger
- Avbryt – lukker dialogen uten å lagre
- Opprett – oppretter en ny datakolleksjon
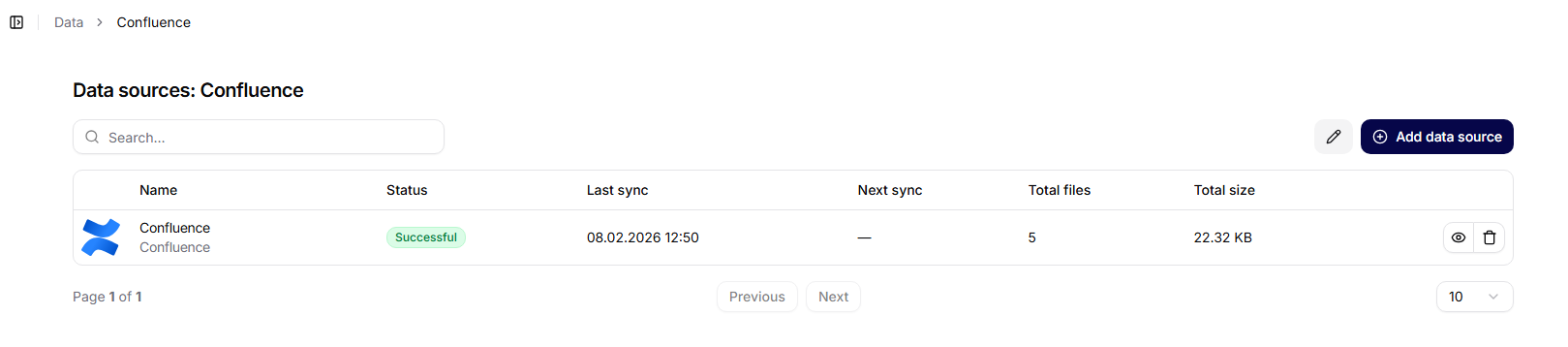
Detalj om datakolleksjon
Når en spesifikk samling åpnes, vises dens detaljside.
Viste informasjon:
- navnet på samlingen,
- dato for opprettelse,
- oversikt over tilkoblede datakilder.
En del av siden er knappen Legg til datakilde.
Legge til datakilde i samlingen
Ved å klikke på Legg til datakilde åpnes et valg for type datakilde.
Tilgjengelige alternativer
- Manual Upload – manuell opplasting av filer
- Google Drive (kommer snart)
- SharePoint (kommer snart)
- Azure Storage (kommer snart)
- Jira (kommer snart)
I den nåværende versjonen er manuell opplasting av filer tilgjengelig.

Konfigurering av datakilde (Manual Upload)
Etter å ha valgt Manual Upload, vises et konfigurasjonsskjema.
Konfigurasjonsfelt
- Navn – navnet på datakilden (f.eks. Big Data).
- Beskrivelse – valgfri beskrivelse av innholdet i datakilden.
- Last opp filer – mulighet til å dra filer inn i det merkede området, eller klikke for å velge filer fra datamaskinen.
- JSON-funksjoner (valgfritt) – brukes til å definere egne funksjoner for arbeid med data.
- JSON-metadata-definisjoner (valgfritt) – gjør det mulig å legge til strukturerte metadata til datakilden.
Handlinger
- Avbryt – forlater konfigurasjonen uten å lagre
- Bekreft – lagrer datakilden og starter behandlingen
Status for datakilde
Hver datakilde har sin egen behandlingsstatus:
- Behandles – dataene blir analysert og indeksert
- Behandlet – datakilden er klar til bruk
Statusen er synlig i tabellen over datakilder i detaljen for samlingen.
Knytte datakolleksjoner til agent
Datakolleksjoner tildeles deretter til agenter i deres innstillinger. Detaljer finner du i delen Konfigurering av agent.
Typisk bruk av datakolleksjoner
Datakolleksjoner brukes hovedsakelig til:
- organisering av større mengder filer,
- samling av data etter tema eller prosjekt,
- oppretting av en enhetlig kilde til sannhet for AI-agenter,
- gjenbruk av de samme dataene i forskjellige arbeidsflyter,
- skalering av arbeidet med data uten behov for duplisering.
Oppsummering
Datakolleksjoner i Siesta AI muliggjør oversiktlig datastyring og effektiv utnyttelse på tvers av hele plattformen. Riktig strukturerte samlinger er grunnlaget for kvalitetsutdata fra AI-agenter og automatiserte arbeidsflyter.